
#머신러닝 #데이터 #AX
머신러닝의 진짜 변수: 데이터로 비즈니스 격차를 만든 기업들
머신러닝의 시작과 끝, 데이터
뛰어난 AI 모델도 물론 중요하지만, AI의 본질은 데이터입니다. AI는 어떤 데이터를 어떤 방식으로 학습(머신러닝)시켰느냐에 따라 그 성능이 결정되는 결과값이기 때문입니다. 오늘은 머신러닝의 개념, 원리를 짚어보면서 기업들이 좋은 데이터를 확보하기 위해 어떤 시스템, 인프라, 프로세스를 설계하는지 살펴보겠습니다.

머신러닝은 데이터를 통해 판단하기 때문에 데이터의 양과 질이 무엇보다 중요하다. / 이미지 출처 AI 생성
이 글에서 이야기할 내용
머신러닝의 개념과 특징, 원리
머신러닝의 핵심 특징 3가지
머신러닝의 원리와 구현 단계
머신러닝의 승부처: 데이터 규모와 품질
데이터로 머신러닝을 비즈니스 무기로 바꾼 기업들
머신러닝의 개념과 특징, 원리
머신러닝이란 무엇인가요?
머신러닝(Machine Learning)
머신러닝(Machine Learning)은 인공지능(AI)의 한 분야로, 컴퓨터가 규칙을 일일이 코딩하지 않아도 데이터로부터 스스로 패턴을 학습하고 예측 및 판단을 가능하게 하는 기술입니다. 머신러닝은 방대한 데이터를 바탕으로 스스로 규칙을 추론하는데요. 덕분에 수천만 개의 픽셀로 이루어진 이미지나 수억 건의 기록 속에서 이상 징후를 찾는 등 복잡한 문제까지도 다룰 수 있습니다.
예를 들어 배송 지연 예측 시스템을 만들려면 “비가 오면 2시간 지연”, “고속도로 정체 시 1.5시간 지연”처럼 사람이 조건을 정의합니다. 반면 머신러닝 모델은 수천 건의 실제 배송 이력에 날씨, 도로 상황, 시간대 등의 변수를 함께 학습해, 어떤 조합에서 얼만큼 지연이 발생하는지 스스로 패턴을 찾아냅니다.
머신러닝의 핵심 특징 3가지
1) 프로그래밍이 아닌 '학습'
기존 소프트웨어는 개발자가 하나하나 코딩합니다. 반면 머신러닝은 데이터를 반복 학습하며 스스로 판단 기준을 만듭니다. 수백 가지 변수가 복잡하게 얽혀있을수록, 사람이 규칙을 일일이 정의하기 어려울수록 머신러닝의 장점은 더 크게 드러나죠.
2) 데이터 기반의 확률적 결과
머신러닝은 완벽한 정답을 내놓는 시스템이 아닙니다. 학습한 패턴을 바탕으로 가장 가능성이 높은 결과를 확률적으로 제시합니다. 예를 들어 배송 지연 예측 모델은 절댓값을 주기보다 ‘지연 확률 87%’를 출력하는 식이죠. 따라서 지속적인 검증과 피드백을 통해 정확도를 높여가는 운영 방식이 필요합니다.
3) 데이터의 양과 질에 따라 달라지는 성능
데이터가 쌓일수록 모델은 점점 정교해집니다. 다만 구조가 불명확하고, 결측이나 오류, 중복이 많고, 핵심 변수와 타깃이 제대로 라벨링되지 않은 데이터는 성능 향상 효과가 떨어집니다. 그래서 글로벌 기업들은 서비스 초기 단계부터 어떤 데이터를 어떤 구조와 품질로 수집할지를 함께 설계합니다.

같은 알고리즘을 써도 투입된 데이터의 양, 품질, 다양성, 최신성에 따라 머신러닝의 성능은 달라질 수 있다. / 이미지 출처 AI 생성
머신러닝의 원리와 구현 단계
머신러닝은 일반적으로 다섯 단계로 이루어집니다.
1) 데이터 수집 | 어떠한 문제를 해결할지 정의하고, 모델 학습에 필요한 데이터를 다양한 출처에서 수집합니다. |
2) 데이터 전처리 | 수집된 데이터를 정리하고 정제합니다. 결측치 처리, 오류 수정, 포맷 통일, 훈련/검증/테스트 데이터 분리 등이 포함됩니다. |
3) 모델 선택 및 학습 | 문제 유형에 맞는 알고리즘을 선택하고 데이터를 바탕으로 모델을 학습시킵니다. 모델의 성능을 측정하는 기준인 손실 함수(Loss Function) 설정한 뒤 손실 함수를 최소화하는 방향으로 파라미터를 반복 조정하며 학습을 진행합니다. |
4) 모델 평가 | 학습된 모델을 검증용 데이터로 테스트하여, 정확도·오차·정밀도 같은 성능 지표를 확인합니다. 이 과정이 충분히 반복되면 모델은 비로소 학습에 사용하지 않은 새로운 데이터에도 정확한 예측을 내놓을 수 있게 됩니다. |
5) 배포 및 실제 활용(예측) | 최종 모델을 실제 환경에 적용해 예측, 분류, 추천 등 실질적인 의사결정에 활용합니다. 운영 중에도 계속 모니터링 및 업데이트가 필요합니다. |
각 단계는 유기적이라 1)데이터의 양이 부족하거나 2)데이터 품질이 떨어지거나 구조가 불명확하면 모델 선택과 손실 함수 설계에도 영향을 미칩니다.
머신러닝의 승부처: 데이터 규모와 품질
머신러닝의 성능을 결정짓는 첫 번째 조건은 데이터의 양입니다. 학습할 데이터가 많을수록 모델은 더 다양한 변수를 경험하며 정교해지기 마련입니다.
그러나 대부분의 데이터 세트는 파편화되었고, 오류(노이즈)가 섞여 있습니다. 그래서 머신러닝에 투자하는 기업들은 데이터의 품질을 높이는 과정에 전체 프로젝트 시간의 80% 이상을 할애합니다.
데이터가 머신러닝 학습에 적합한 형태로 변모하는 과정은 크게 세 가지 단계로 요약됩니다.
단계 | 세부 과정 |
1단계. 데이터 정제 (Cleaning) | 중복된 레코드나 시스템 오류로 발생한 비정상적인 값(이상치)을 제거하고 수정하여 데이터의 순도를 높임 |
2단계. 데이터 완성(Completing) | 비어있는 값(결측치)을 통계적 방법으로 채우거나, 서로 다른 데이터 소스를 결합해 누락된 정보를 보완하여 데이터의 완결성 확보 |
3단계. 데이터 구조화(Structuring) | 변수의 형식과 단위를 통일하고, 모델이 학습하기 가장 좋은 형태로 데이터 재구성 |
머신러닝을 선도하는 기업들은 이러한 과정을 자동화된 파이프라인과 데이터 거버넌스 체계로 구축하고 있습니다. 특히 수집되는 데이터의 양이 압도적일수록 정제 시스템의 역할은 더욱 막중해집니다. 이들은 예측 결과와 실제값을 대조하는 피드백 루프를 통해 데이터의 질을 개선하며 데이터 자산의 가치를 높입니다.
데이터로 머신러닝을 비즈니스 무기로 바꾼 기업들
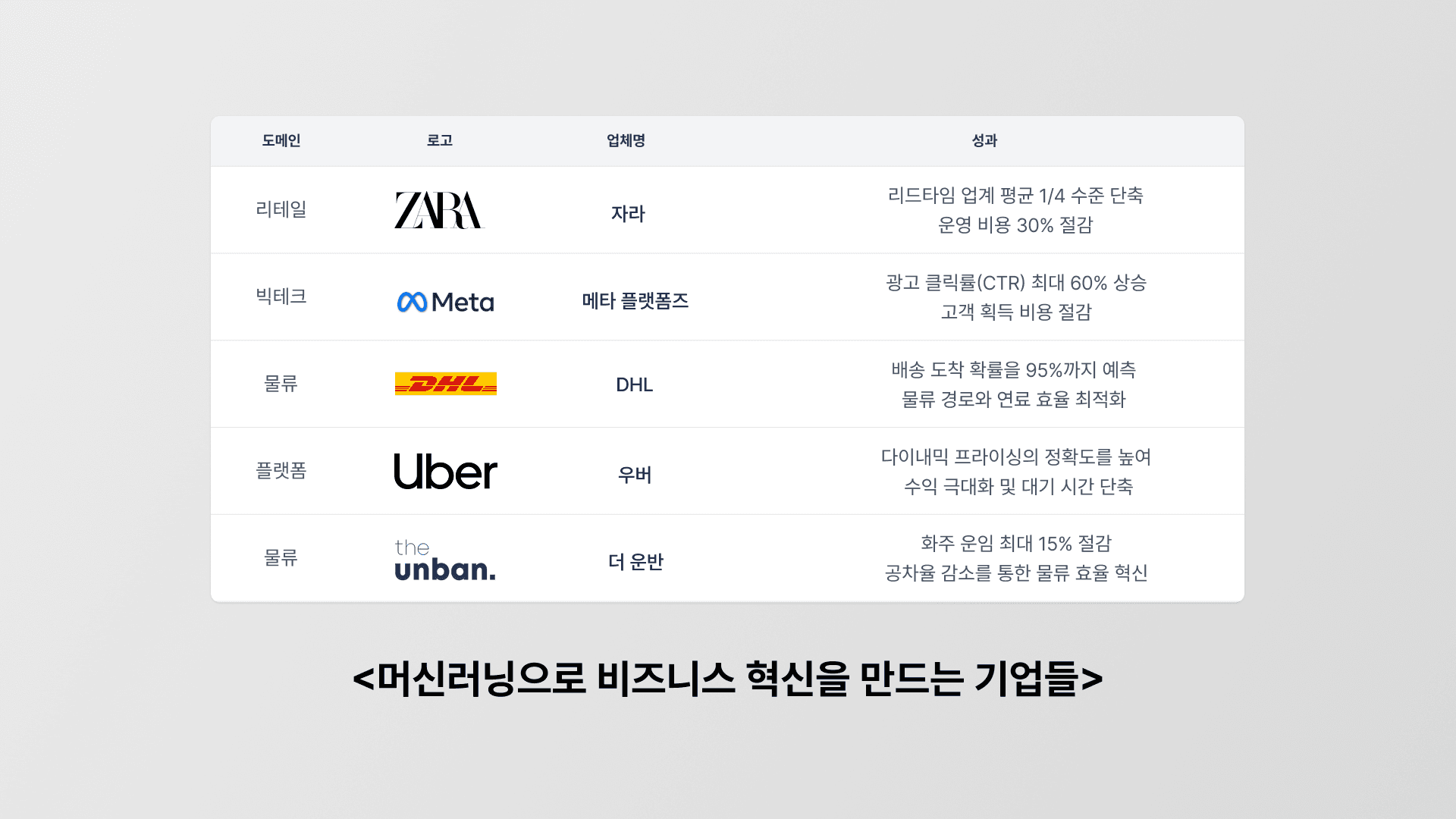
데이터의 양과 질이 시너지를 이룰 때 기업들은 머신러닝을 통해 어떠한 성과를 만들어낼까요?
1) 자라(Zara), 패션 리테일
자라(Zara)는 매장의 POS 데이터, 온라인 행동 로그, RFID 기반의 실시간 재고 추적 데이터에 날씨와 소셜미디어 트렌드 같은 외부 변수를 결합하여 데이터 세트를 구축합니다. 이때 자라는 모든 데이터를 SKU(상품 관리 단위)와 매장, 시간 단위로 표준화하여 재구성합니다.
이렇게 정제된 데이터로 자라의 머신러닝은 특정 스타일의 옷을 어느 매장에 얼마나 배분할지, 추가 주문이 필요한 시점은 언제인지, 창고에서 매장으로 재고를 이동시킬 적기는 언제인지를 스스로 제안합니다. 게다가 고객의 클릭 패턴과 구매 이력을 분석해 개인화된 마케팅 프로모션을 제공하며 고객 경험의 품질을 높이고 있습니다.
그 결과 자라는 정교한 수요 예측을 통해 과잉 재고와 판매 손실을 동시에 억제하며 운영 비용을 약 30% 절감하는 데 성공했습니다. 특히 디자인부터 매장 진열까지 걸리는 리드타임을 업계 평균인 12~16주의 절반 이하인 3주 수준으로 단축했습니다.

2) 메타 플랫폼즈(Meta Platforms), 빅테크
전 세계 30억 명 이상의 사용자 데이터를 보유한 메타(Meta)는 클릭, 좋아요, 영상 시청 시간 등 방대한 행동 데이터를 실시간으로 수집합니다. 또한 메타 머신러닝의 진짜 강점은 수천만 개의 파편화된 변수를 사용자 및 광고 ID 단위로 재구조화하여 노이즈를 제거하고, 학습에 최적화된 고순도 데이터를 생성해냅니다.
메타는 픽셀(Pixel)과 전환 API(Conversion API)를 통해 수집된 데이터를 플랫폼, 장치, 시간 단위로 정밀하게 재구성합니다. 이 과정에서 보정을 통해 누락된 전환 이벤트를 복원하고, 의도치 않은 클릭이나 오류 로그 같은 노이즈를 제거하여 데이터의 신뢰도를 높입니다. 특히 사용자의 실제 반응을 실시간으로 모델에 다시 입력하는 '피드백 루프(Feedback Loop)'를 구축하여 머신러닝이 진짜 성과를 지속적으로 학습하도록 데이터를 고도화합니다.
이렇게 정제된 데이터 세트는 클릭률(CTR)과 전환율(CVR)을 확률적으로 예측합니다. 이를 기반으로 머신러닝 모델은 특정 광고를 어떤 사용자에게, 어느 채널에서 노출하는 것이 가장 효과적일지 계산하여 광고 경매 과정에 반영합니다. 또한 성과가 좋은 광고에는 자동으로 예산을 집중 배분하고 저성과 광고는 노출을 줄이는 구조를 통해 시스템 스스로 성과를 확장해 나가는 지능형 운영을 실현하고 있습니다.
머신러닝을 통해 메타는 광고 클릭률(CTR)을 약 30~60%까지 끌어올렸으며, 전환 가능성이 높은 타겟에 집중함으로써 고객 획득 비용(CPA)을 10~30% 절감하는 성과를 거두었습니다.

이미지 출처: Search Engine Journal
3) DHL, 물류
DHL은 배송 시간을 예측하고 경로를 최적화하는 데 머신러닝을 활용합니다. 여기에 쓰이는 데이터는 배송 차량의 GPS 위치, 과거 배송 기록, 교통 상황, 날씨, 물류 허브 처리 시간, 배송 물량 등 실시간으로 수집되는 전 세계 물류 네트워크에서 발생하는 배송 및 운영 데이터입니다. 이 데이터는 모두 머신러닝 모델에 입력되어 ETA(예상 배송 시간)를 예측하고, 동시에 최적의 배송 경로를 계산하는 데 사용됩니다. 또한 시간대별 교통 혼잡, 지역별 배송 밀도, 물류 거점의 처리 속도까지 반영해 경로를 동적으로 재조정합니다. 특정 지역에서 예상보다 배송이 지연될 가능성이 높아지면, 다른 차량으로 물량을 재배분하거나 우회 경로를 자동으로 추천하는 방식으로 운영 효율을 높입니다.
이때 DHL은 GPS, AIS(선박 자동 식별 시스템), 터미널 로그 등 서로 다른 출처의 데이터를 통합 데이터 레이크에 모아 통일된 형식으로 재구성합니다. 특히 데이터 거버넌스 프레임워크를 통해 타임스탬프의 정확성을 유지하고 머신러닝 모델이 항상 신뢰할 수 있는 최신 정보를 학습할 수 있는 환경을 구축했습니다.
실제로 DHL은 특정 배송 물량이 특정 시점과 시설에 도착할 확률을 90~95% 수준으로 예측할 수 있을 만큼 ETA 정확도를 높여 배송 지연을 줄였으며, 이를 기반으로 배송 경로와 물량 배분을 더욱 정밀하게 계획할 수 있게 되었다고 합니다. 또한 최대 120개 정류장을 수 초 내에 분석해 배송 우선순위와 이동 경로를 재구성하면서 배송 시간을 단축하고 연료 사용도 줄여 나가고 있습니다.

이미지 출처 DHL Supply Chain
4) 우버(Uber), 플랫폼
우버(Uber)는 전 세계 수백 개 도시에서 발생하는 승객 요청과 운전자 위치 데이터를 실시간으로 수집합니다. GPS 위치, 운전자 상태, 과거 운행 기록뿐 아니라 시간대, 날씨, 지역 이벤트 같은 외부 신호까지 함께 활용합니다. 우버 역시 각기 다른 도시 환경에서 발생하는 수많은 변수를 공통된 규격으로 재구성합니다. 이 과정에서 중복된 로그나 시스템 오류로 인한 이상치를 제거하고 피드백 루프를 보유하고 있습니다.
이 데이터를 바탕으로 머신러닝 모델은 최적의 승객과 운전자를 매칭하고, 수요가 몰리는 지역에 운전자를 사전 배치해 대기 시간을 최소화합니다. 또한 실시간 교통 데이터를 반영해 승객에게 정확한 도착 예정 시간을 제공하고, 머신러닝 기반 이상 탐지 플랫폼 'Risk Entity Watch'를 통해 사기나 부정 행위를 실시간으로 감지합니다.
특히 주목할 만한 건 다이나믹 프라이싱(Dynamic Pricing) 전략입니다. 출퇴근 시간이나 날씨, 이벤트로 수요가 급증하면 요금을 올리고, 수요가 적은 시간대에는 요금을 낮춰 운전자 참여를 유도하는 방식입니다. 요금은 1.2배에서 최대 8배까지 적용되며, 이 가격 계산 과정에서도 지역 상황, 기후, 교통 데이터를 실시간으로 반영하는 머신러닝 알고리즘이 작동합니다.
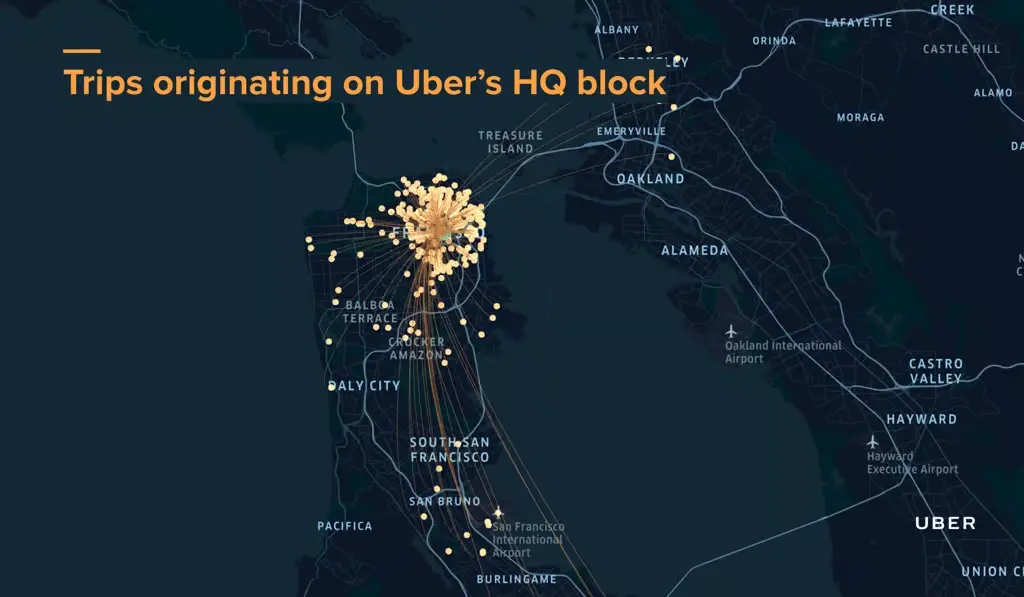
우버 본사 블록에서 출발하는 이동 경로를 시각화한 지도로, 지도 내 데이터와 머신러닝을 결합해 최적의 목적지를 추천한다. / 이미지 출처 우버 블로그
5) CJ대한통운 더 운반, 물류
물류 산업에서 데이터와 머신러닝의 결합은 글로벌 기업만의 이야기가 아닙니다. CJ대한통운의 더 운반은 기업 물류의 운송구조를 최적화 하기 위해, 운영 과정에서 수집되는 주문 패턴, 배차 이력, 운송 구간별 수요, 계절성, 화물 특성, 차주 수급 등의 데이터를 머신러닝에 활용합니다.
데이터는 학습을 거쳐 운임 산정, 차량 매칭, 경로 설계에 연결됩니다. 화물 종류, 이동 거리, 시장 상황(유가·날씨·계절성 등)을 종합 분석해 실시간으로 최적 운임을 계산하고, 차주의 위치와 운행 이력을 반영해 가장 적합한 차량을 자동으로 매칭하는 방식으로 작동합니다. 같은 원리로 과거의 교통 데이터와 운송 이력을 학습해 향후 교통량과 운행 시간을 예측하고 최적 운송 경로를 제안합니다.
이 알고리즘을 통해 매칭된 플랫폼 화주는 평균 5~15% 수준의 운임 절감 효과를 얻고 있으며, 더 운반은 복화, 경유, 합짐 등 데이터 기반 운송 모델을 적용해 공차율을 줄이고 운송 효율을 높이는 실험을 지속하고 있습니다. 현재 4,000개 이상의 기업 고객과 4만 명 이상의 차주가 더 운반을 통해 미들마일 운송 시장의 변화를 만들어가고 있습니다.
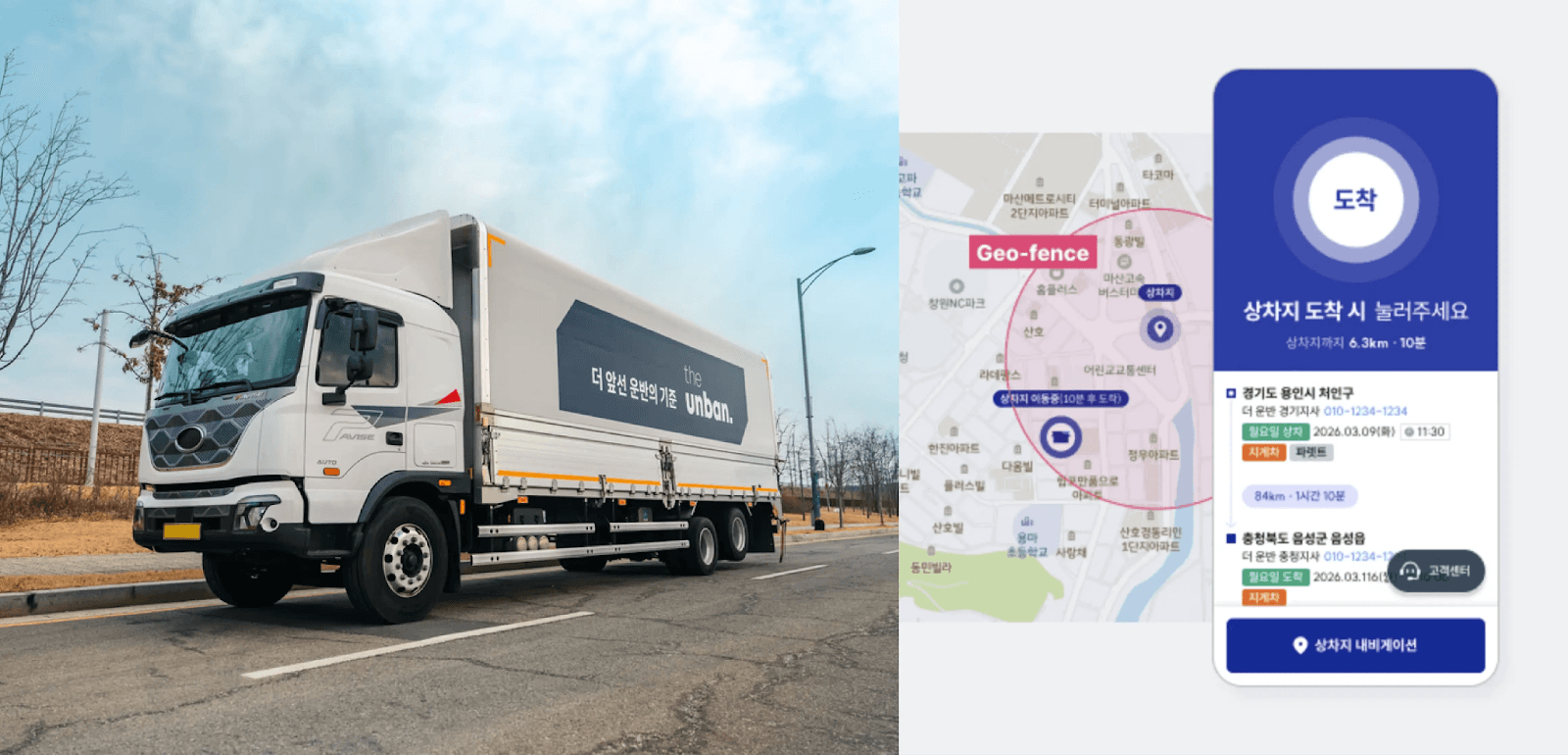
CJ대한통운 더 운반은 국내 최대의 운송 데이터를 기반으로한 머신러닝으로 국내 물류 산업 AX에 앞장서고 있다. 출처더 운반 블로그
모든 산업의 경쟁력, 머신러닝과 데이터
AX는 이제 전 산업에서 이루어집니다. 패션, 항공, 물류, 플랫폼까지 업종과 규모가 다른 기업들이 데이터를 통해 비즈니스 성과를 만들어내고 있습니다. 핵심은 고객의 실제 행동이 담긴 현장 데이터를 쌓는 일입니다. 이제 데이터는 기업의 흥망을 결정하는 변수 중 하나라고 할 수 있어요.

국내에서 가장 똑똑한 AI 운송 기업, ‘더 운반’
운송는 데이터가 가장 풍부하게 발생하는 산업 중 하나입니다. 그러나 데이터가 많다고 해서 자동으로 경쟁력이 생기는 건 아닙니다.
CJ대한통운 ‘더 운반’은 96년간 축적된 미들마일 운송 데이터를 기반으로 AI를 활용한 운임 최적화와 운송 모델 혁신을 실현하고 있습니다. '계약운송' 서비스를 통해 자체 알고리즘이 산출한 최적화된 운임을 만나볼 수 있는 것이 그 예시이죠.
현장의 노하우와 데이터에 AI를 결합한 국내 운송 시장의 AX(AI 전환) 혁신, 지금 바로 더 운반 블로그에서 확인해 보세요.



" height="14.564px" id="lwjR1JUeW" transform="translate(0.017 21.436)" width="13.248117039010587px"/><path d="M 13.303 5.922 L 13.303 14.522 L 8.671 14.522 L 8.671 6.594 C 8.671 4.952 8.084 4.138 6.918 4.138 C 5.474 4.138 4.643 5.196 4.643 6.99 L 4.643 14.522 L 0 14.522 L 0 0.418 L 3.898 0.418 L 3.898 1.872 C 4.9 0.702 6.393 0 8.13 0 C 11.253 0 13.303 2.328 13.303 5.92 Z" fill="rgb(255, 255, 255)" height="14.522000000000013px" id="wgAIf9jpg" transform="translate(66.346 21.016)" width="13.302619266055046px"/><path d="M 13.303 5.922 L 13.303 14.522 L 8.671 14.522 L 8.671 6.594 C 8.671 4.952 8.083 4.138 6.918 4.138 C 5.474 4.138 4.643 5.196 4.643 6.99 L 4.643 14.522 L 0 14.522 L 0 0.418 L 3.898 0.418 L 3.898 1.872 C 4.9 0.702 6.392 0 8.13 0 C 11.253 0 13.303 2.328 13.303 5.92 Z" fill="rgb(255, 255, 255)" height="14.522000000000013px" id="BIGgr3j5p" transform="translate(16.041 21.016)" width="13.302539449541271px"/><path d="M 7.92 4.652 C 12.061 4.652 14.984 7.772 14.984 12.154 C 14.984 16.536 12.059 19.656 7.92 19.656 C 6.352 19.656 4.956 19.104 3.865 18.148 L 3.865 19.196 L 0 19.196 L 0 0 L 4.579 0 L 4.579 5.626 C 5.542 5.002 6.677 4.654 7.92 4.654 Z M 10.31 12.154 C 10.31 10.312 9.035 8.938 7.299 8.938 C 5.563 8.938 4.289 10.312 4.289 12.154 C 4.289 13.996 5.563 15.356 7.299 15.356 C 9.035 15.356 10.31 13.982 10.31 12.154 Z" fill="rgb(255, 255, 255)" height="19.655999959217986px" id="g2IyTwo_p" transform="translate(32.117 16.342)" width="14.98387431192657px"/><path d="M 15.083 0.426 L 15.083 14.528 L 11.158 14.528 L 11.158 13.53 C 10.057 14.466 8.611 15.004 7.05 15.004 C 2.938 15.004 0 11.858 0 7.476 C 0 3.094 2.938 0 7.05 0 C 8.634 0 10.047 0.554 11.158 1.516 L 11.158 0.426 Z M 7.667 10.704 C 9.403 10.704 10.677 9.33 10.677 7.488 C 10.677 5.646 9.403 4.282 7.667 4.282 C 5.931 4.282 4.657 5.656 4.657 7.488 C 4.657 9.32 5.931 10.704 7.667 10.704 Z" fill="rgb(255, 255, 255)" height="15.004000028233783px" id="WHPE56MNu" transform="translate(48.49 20.994)" width="15.083086238532104px"/><path d="M 0 0 L 4.578 0 L 4.578 4.706 L 0 4.706 Z" fill="rgb(255, 255, 255)" height="4.705999999999996px" id="h7AUXfduL" transform="translate(82.422 30.832)" width="4.578275229357786px"/><path d="M 3.141 0 L 2.287 0 L 2.287 3.236 L 0 3.236 L 0 4.052 L 2.287 4.052 L 2.287 10.65 C 2.287 12.724 3.497 14.012 5.449 14.012 L 6.766 14.012 L 6.766 13.152 L 5.501 13.152 C 4.003 13.152 3.143 12.232 3.143 10.626 L 3.143 4.052 L 6.682 4.052 L 6.682 3.236 L 3.143 3.236 L 3.143 0 Z" fill="rgb(255, 255, 255)" height="14.012000000000004px" id="WfExQLKOi" width="6.766101743119265px"/><path d="M 0.854 0 L 0 0 L 0 14.006 L 0.854 14.006 L 0.854 7.706 C 0.854 5.66 2.279 3.996 4.343 3.996 C 6.408 3.996 7.922 5.318 7.922 7.716 L 7.922 14.006 L 8.776 14.006 L 8.776 7.608 C 8.776 4.814 6.972 3.146 4.375 3.146 C 2.75 3.146 1.376 3.994 0.854 5.162 Z" fill="rgb(255, 255, 255)" height="14.005996052664393px" id="LfJXvS6nI" transform="translate(8.844 0.004)" width="8.77630458096327px"/><path d="M 5.023 0 C 2.16 0 0 2.336 0 5.434 C 0 8.532 2.158 10.896 5.023 10.896 C 7.056 10.896 8.693 9.762 9.631 7.702 L 9.714 7.518 L 8.825 7.518 L 8.79 7.588 C 8.01 9.168 6.671 10.04 5.023 10.04 C 2.717 10.04 0.971 8.248 0.831 5.762 L 9.934 5.762 L 9.942 5.64 C 9.946 5.558 9.952 5.46 9.952 5.376 C 9.952 2.31 7.834 0 5.024 0 Z M 0.845 4.932 C 1.059 2.554 2.796 0.842 5.024 0.842 C 7.253 0.842 8.926 2.516 9.121 4.932 Z" fill="rgb(255, 255, 255)" height="10.896008000000002px" id="Z8G0y4oLR" transform="translate(19.393 3.142)" width="9.951602752293589px"/></g></svg>)